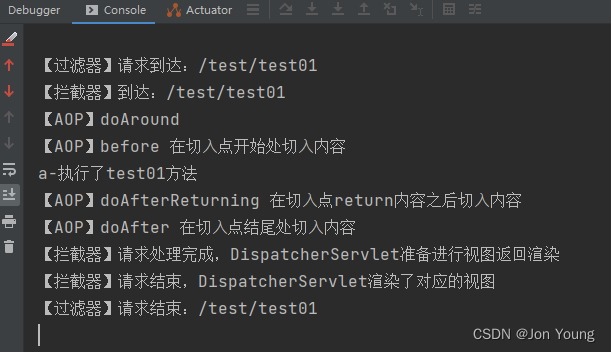
四、(3)补充beautifulsoup、re正则表达式、标签解析
- beautifulsoup
- re正则表达式
- 正则提取
- 标签解析
beautifulsoup
补充关于解析的知识
还需要看爬虫课件
如何定位文本或者标签,是整个爬虫中非常重要的能力
无论find_all()还是select()选择器是很重要的
下方为baidu.com简单的素材
baidu.html
<!DOCTYPE html>
<html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="content-type" />
<meta content="IE=Edge" http-equiv="X-UA-Compatible" />
<meta content="always" name="referrer" />
<link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css" />
<title>百度一下,你就知道 </title>
</head>
<body link="#0000cc">
<div id="wrapper">
<div id="head">
<div class="head_wrapper">
<div id="u1">
<a class="mnav" href="http://news.baidu.com" name="tj_trnews"><!--新闻--></a>
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123</a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图</a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频</a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧</a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">更多产品 </a>
</div>
</div>
</div>
</div>
</body>
</html>
模拟爬虫爬取到网页后,如就想要里面的文字,里面的连接,或者指定某个样子的文字,某种类型,就需要匹配的工具来帮助
#-*- codeing = utf-8 -*-
#@Time : 2020/11/21 16:00
#@Author : 招财进宝
#@File : testBs4.py
#@Software: PyCharm
'''
BeaufifulSoup 将复杂HTML文档转换成一个复杂的树形结构,每个节点都是python对象,所有对象可以归纳为4种:
-Tag
-NavigableString
-BeautifulSoup
-Comment
'''
from bs4 import BeautifulSoup
file = open("./baidu.html","rb") #以rb,readbytes(二进制读取)的方式读取某个文件,读到内存中
html = file.read() #将文件内容读取到对象html中 或者 html = file.read() .decode("utf-8")
bs = BeautifulSoup(html,"html.parser") #使用对象bs帮助解析文档,使用解析器html.parser解析上面的文档
'''
#print(bs.title)
print(bs.a) #使用此种方式时,拿到的是第一个标签及其所有内容<a class="mnav" href="http://news.baidu.com" name="tj_trnews"><!--新闻--></a>
#print(bs.head)
print(type(bs.a)) #<class 'bs4.element.Tag'>
#1.Tag(常用排名3) 标签及其内容:只能拿到它所找到的第一个内容
print(bs.title.string) #百度一下,你就知道
print(type(bs.title.string)) #<class 'bs4.element.NavigableString'>
#2.NavigableString(常用排名2) 标签里的内容(字符串)
'''
'''
#可以快速拿到一个标签中的所有属性
print(bs.a.attrs) #里面是键值对{'class': ['mnav'], 'href': 'http://news.baidu.com', 'name': 'tj_trnews'}
print(type(bs.a.attrs)) #<class 'dict'>,字典的方式
print(type(bs)) #<class 'bs4.BeautifulSoup'>
#3.BeautifulSoup(最常用排名第一) 表示整个文档,bs就是整个文档的内容,可以对bs直接操作
print(bs)
'''
'''
print(bs.a.string) #新闻,本来是<!--新闻-->,但注释没了
print(type(bs.a.string)) #<class 'bs4.element.Comment'>
#4.Comment 是一个特殊的NavigableString,但输出的内容会不包含注释符号
'''
#---------------------------------------------------(以下是应用)
#文档的遍历(将文档中相似的找到)(全部找到,此处了解,以后用到再看)
#print(bs.head.contents) #返回了一个列表,将head中所有标签,以列表的形式组装
#print(bs.head.contents[1]) #使用列表下标的方式
#文档的搜索(希望根据文字搜所,文字结构搜索,特点搜索)(重点,拿到特定的内容)
#如何在HTML中定位我们想要的内容
'''
#(1)find_all()(最经常使用的)
#字符串过滤:会查找与字符串完全匹配的内容
t_list = bs.find_all("a") #能够查找所有的a标签,必须是单个a,不是只要含有a的就可以,放入列表中
print(t_list)
#正则表达式搜索:使用search()方法来匹配内容
import re
t_list = bs.find_all(re.compile("a")) #正则表达式编译一个对象,re.compile("a")。再使用find_all寻找
#此处是将所有含有a的字母的标签 ,正则匹配某个标签及其内容,只要标签含有a,就将其及其内容找到
print(t_list)
'''
'''
#方法:传入一个函数(方法),根据函数的要求来搜索(了解即可)
def name_is_exists(tag):
return tag.has_attr("name") #传入标签tag,返回“name”的值的
t_list= bs.find_all(name_is_exists)
print(t_list)
'''
'''
#2.kwargs 参数
#t_list = bs.find_all(id = "head") #这里传入的不再是具体规则,而是参数
t_list = bs.find_all(href="http://news.baidu.com")
#t_list = bs.find_all(class_=True) #只要class存在的就将其及其子内容显示
for item in t_list:
print(item)
'''
'''
#3.text 参数
#t_list = bs.find_all(text = "hao123") #找到一个特定文本的内容就打印出来
#t_list = bs.find_all(text = ["hao123","地图","贴吧"]) #也可以找到列表
import re
#使用正则表达式来查找包含特定文本的内容(标签里的字符串)
t_list = bs.find_all(text = re.compile("\d")) #"\d" 表示数字,将所有是数字文本找到
for item in t_list:
print(item)
'''
'''
#4.limit 参数
t_list = bs.find_all("a",limit=3) #limit可以限定你到底获取多少个
for item in t_list:
print(item)
'''
'''
#css选择器
#t_list = bs.select("title") #通过标签来查找
#t_list = bs.select(".mnav") #“.”表示类名查找,后面是类名,class="mnav"
#t_list = bs.select("#u1") #通过id来查找<div id="u1">
#t_list = bs.select("a[class='bri']") #通过a标签的属性class='bri'查找
#t_list = bs.select("head > title") #通过子标签来查找,将head标签下的title找到
# for item in t_list:
# print(item)
t_list = bs.select(".mnav ~ .bri") #跟mnav是兄弟的一个标签,而且这个兄弟是bri
print(t_list[0].get_text())
'''
re正则表达式
判断写的字符串是否符合标准,如邮箱是否以邮箱的格式结尾,如是否有@或者.com等
.*@126.com
史上最全常用正则表达式大全
https://www.cnblogs.com/fozero/p/7868687.html
里面有各个各样的格式,可以应用参考
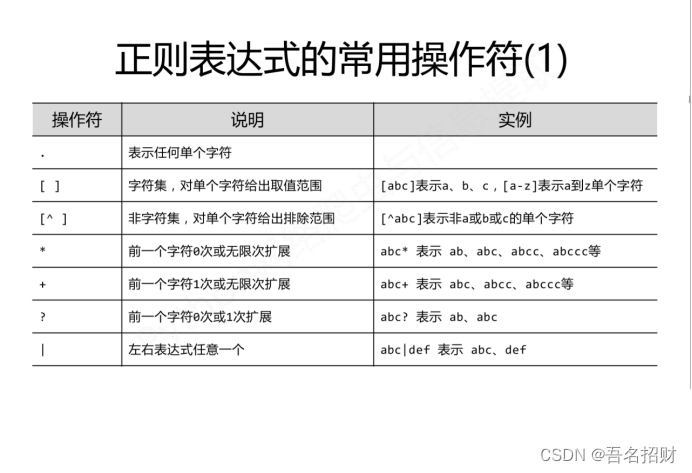
先看上方的
abc* ab是必须存在的,后面的c可以有0个,也可以有无限个
abc+ ab是必须存在的,后面的c至少1个,也可以有无限个
正则表达式,符号组合形成固定模式
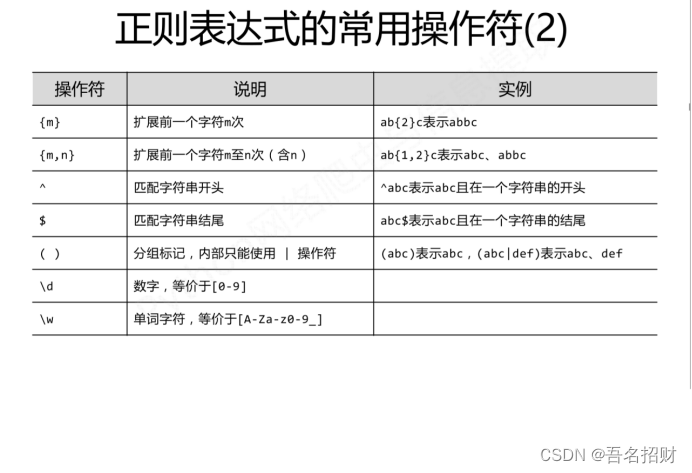
正则表达式基本是表示一位的字符
\d 表示单个数字
\w 表示大写A-Z,小写a-z,数字0-9,再加上下划线,很多国外的网站的用户名必须是如此
正则表达式,在各个语言中都有对应的库可以使用

只有match、findall、sub等用的最多

需要掌握
re.l先忽略大小写然后再进行比较
re.S扩大了范围,将包括换行符在内的字符也进行匹配
#-*- codeing = utf-8 -*-
#@Time : 2020/11/23 9:08
#@Author : 招财进宝
#@File : testRe.py
#@Software: PyCharm
#正则表达式:字符串模式(判断字符串是否符合一定的标准)
import re
'''
#创建模式对象
pat = re.compile("AA") #此处的AA是正则表达式,用来取验证其他的字符串
m = pat.search("CBA") #search字符串被校验的内容
print(m) #None
m = pat.search("ABCAA") #search字符串被校验的内容
print(m) #<re.Match object; span=(3, 5), match='AA'> ,左闭右开,[3,5)
m = pat.search("ABCAADDCCAAA") #search字符串被校验的内容
print(m) #使用search方式只能找到第一个找到的AA,<re.Match object; span=(3, 5), match='AA'>
'''
#没有模式对象
# m = re.search("asd","Aasd") #前面的字符串是规则(模板),后面的字符串是被校验的对象
# print(m)
#print(re.findall("a","ASDaDFGAa")) #前面的字符串是规则,后面的字符串是被校验的对象
# 得到列表['a', 'a'],找到所有符合此标准的字符串
#print(re.findall("[A-Z]","ASDaDFGAa")) #找一个大写字母,将所有的大写字母一个个的找出来['A', 'S', 'D', 'D', 'F', 'G', 'A']
#print(re.findall("[A-Z]+","ASDaDFGAa")) #[A-Z]+,A-Z中至少出现一个字母,但是出现多个也是可以的没有问题的['ASD', 'DFGA']
#sub 起到分割替换的作用
#print(re.sub("a","A","abcdcasd")) #找到a用A替换,第一个是被替换的对象,第二个是要换成的对象,在第三个字符串中找到
#在以后的换行等操作,可以使用sub替换成空格,这样就不换行了,等等替换操作
#建议在正则表达式中,被比较的字符串前面加上r,不用担心转义字符的问题
a=r"\aabd-\'"
b="\aabd-\'"
print(a,b) #\aabd-\' _x0007_abd-'
正则提取
正则表达式和标签解析是可以相互嵌套的
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10): #此处是爬取10页是数据,每页有25个电影数据((0,10)左闭,右开)
url = baseurl + str(i*25) #每一页的url后的起始位置=页数*25
html = askURL(url) #保存获取到的网页源码
# 2.逐一解析数据(每个网页解析一下)
soup = BeautifulSoup(html,"html.parser") #使用html解析器html.parser解析html
# find_all()查找符合要求的字符串,形成列表
for item in soup.find_all('div',class_="item"): #class是个类别需要加下划线,将及时div又是class_="item"的标签找到
print(item)
return datalist #返回数据列表
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
</a>
</div>
<div class="info">
<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span content="10.0" property="v:best"></span>
<span>2192162人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
findLink = re.compile(r'a href="(.*?)">') #生成正则表达式对象,表示规则(字符串的模式),用来匹配所有的链接
def getData(baseurl):
datalist=[]
for i in range(0,1): #此处是爬取10页是数据,每页有25个电影数据((0,10)左闭,右开)
url = baseurl + str(i*25) #每一页的url后的起始位置=页数*25
html = askURL(url) #保存获取到的网页源码
# 2.逐一解析数据(每个网页解析一下)
soup = BeautifulSoup(html,"html.parser") #使用html解析器html.parser解析html
# find_all()查找符合要求的字符串,形成列表
for item in soup.find_all('div',class_="item"): #class是个类别需要加下划线,将及时div又是class_="item"的标签找到
#print(item) #测试:查看电影item全部信息
#print(type(item))
data=[] #保存一部电影的所有信息
item = str(item) #str将item变成字符串
#print(item)
#print(type(item))
#接下来可以使用正则表达式对字符串进行解析了
link = re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串,获取两个相同的链接中的第一个
print(link)
return datalist #返回数据列表
获取链接
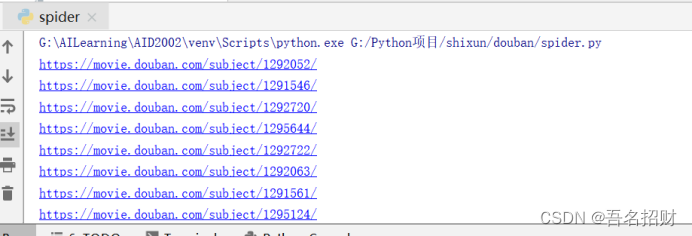
标签解析
Beautifulsoup
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
</a>
</div>
<div class="info">
<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span content="10.0" property="v:best"></span>
<span>2192162人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
#影片详情链接的规则
findLink = re.compile(r'a href="(.*?)">') #生成正则表达式对象,表示规则(字符串的模式),用来匹配所有的链接
#影片 图片的链接
findImgSrc = re.compile(r'<img.*src="(.*?)"',re.S) #re.S忽略里面的换行符,让换行符包含在字符中
#影片片名
findTitle = re.compile(r'<span class="title">(.*)</span>')
#影片的评分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
#找到评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>')
#找到概况
findIng = re.compile(r'<span class="inq">(.*)</span>')
#找到影片的相关内容
findBd = re.compile(r'<p class="">(.*)</p>',re.S) #re.S忽略里面的换行符,让换行符包含在字符中
规则已经找到,如何
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10): #此处是爬取10页是数据,每页有25个电影数据((0,10)左闭,右开)
url = baseurl + str(i*25) #每一页的url后的起始位置=页数*25
html = askURL(url) #保存获取到的网页源码
# 2.逐一解析数据(每个网页解析一下)
soup = BeautifulSoup(html,"html.parser") #使用html解析器html.parser解析html
# find_all()查找符合要求的字符串,形成列表
for item in soup.find_all('div',class_="item"): #class是个类别需要加下划线,将及时div又是class_="item"的标签找到
#print(item) #测试:查看电影item全部信息
#print(type(item))
data=[] #保存一部电影的所有信息
item = str(item) #str将item变成字符串
#print(item)
#print(type(item))
#break #用来测试第一条item
#接下来可以使用正则表达式对字符串进行解析了
#影片详情的链接
link = re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串,获取两个相同的链接中的第一个
#print(link)
data.append(link) #添加链接
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc) #添加图片
titles = re.findall(findTitle,item) #片名可能只有一个中文名,没有外文名
if(len(titles)==2) :
ctitle =titles[0] #中文名的标题
data.append(ctitle)
otitle = titles[1].replace("/","") #去掉无关的符号
data.append(otitle) #添加外国名
else:
data.append(titles[0]) #将第一个中文名填入
data.append(' ') #留空,用于占据外国名的位置,防止位置不对称
rating = re.findall(findRating,item)[0]
data.append(rating) #添加评分
judgeNum = re.findall(findJudge,item)[0]
data.append(judgeNum) #添加评价人数
inq = re.findall(findIng,item)[0]
#(不一定每个电影都有概述)
if len(inq) !=0:
inq=inq[0].replace("。","") #去掉句号
data.append(inq) #添加概述
else:
data.append(" ") #留空
bd = re.findall(findBd,item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?'," ",bd) #去掉<br/>
bd = re.sub('/'," ",bd) #替换/
data.append(bd.strip()) #去掉前后的空格
datalist.append(data) #把处理好的一部电影信息放入datalist
print(datalist)
return datalist #返回数据列表
[['https://movie.douban.com/subject/1292052/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg', '肖申克的救赎', '\xa0\xa0The Shawshank Redemption', '9.7', '2192734', '希', '导演: 弗兰克·德拉邦特 Frank Darabont\xa0\xa0\xa0主演: 蒂姆·罗宾斯 Tim Robbins ... 1994\xa0 \xa0美国\xa0 \xa0犯罪 剧情'], ['https://movie.douban.com/subject/1291546/', 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2561716440.jpg', '霸王别姬', ' ', '9.6', '1626317', '风', '导演: 陈凯歌 Kaige Chen\xa0\xa0\xa0主演: 张国荣 Leslie Cheung 张丰毅 Fengyi Zha... 1993\xa0 \xa0中国大陆 中国香港\xa0 \xa0剧情 爱情 同性'], ['https://movie.douban.com/subject/1292720/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2372307693.jpg', '阿甘正传', '\xa0\xa0Forrest Gump', '9.5', '1653798', '一', '导演: 罗伯特·泽米吉斯 Robert Zemeckis\xa0\xa0\xa0主演: 汤姆·汉克斯 Tom Hanks ... 1994\xa0 \xa0美国\xa0 \xa0剧情 爱情'], ['https://movie.douban.com/subject/1295644/', 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p511118051.jpg', '这个杀手不太冷', '\xa0\xa0Léon', '9.4', '1838229', '怪', '导演: 吕克·贝松 Luc Besson\xa0\xa0\xa0主演: 让·雷诺 Jean Reno 娜塔莉·波特曼 ... 1994\xa0 \xa0法国 美国\xa0 \xa0剧情 动作 犯罪'], ['https://movie.douban.com/subject/1292722/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p457760035.jpg', '泰坦尼克号', '\xa0\xa0Titanic', '9.4', '1608683', '失', '导演: 詹姆斯·卡梅隆 James Cameron\xa0\xa0\xa0主演: 莱昂纳多·迪卡普里奥 Leonardo... 1997\xa0 \xa0美国\xa0 \xa0剧情 爱情 灾难'], ['https://movie.douban.com/subject/1292063/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2578474613.jpg', '美丽人生', '\xa0\xa0La vita è bella', '9.5', '1025570', '最', '导演: 罗伯托·贝尼尼 Roberto Benigni\xa0\xa0\xa0主演: 罗伯托·贝尼尼 Roberto Beni... 1997\xa0 \xa0意大利\xa0 \xa0剧情 喜剧 爱情 战争'], ['https://movie.douban.com/subject/1291561/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2557573348.jpg', '千与千寻', '\xa0\xa0千と千尋の神隠し', '9.4', '1722688', '最', '导演: 宫崎骏 Hayao Miyazaki\xa0\xa0\xa0主演: 柊瑠美 Rumi Hîragi 入野自由 Miy... 2001\xa0 \xa0日本\xa0 \xa0剧情 动画 奇幻'], ['https://movie.douban.com/subject/1295124/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p492406163.jpg', '辛德勒的名单', "\xa0\xa0Schindler's List", '9.5', '843687', '拯', '导演: 史蒂文·斯皮尔伯格 Steven Spielberg\xa0\xa0\xa0主演: 连姆·尼森 Liam Neeson... 1993\xa0 \xa0美国\xa0 \xa0剧情 历史 战争'], ['https://movie.douban.com/subject/3541415/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2616355133.jpg', '盗梦空间', '\xa0\xa0Inception', '9.3', '1607435', '诺', '导演: 克里斯托弗·诺兰 Christopher Nolan\xa0\xa0\xa0主演: 莱昂纳多·迪卡普里奥 Le... 2010\xa0 \xa0美国 英国\xa0 \xa0剧情 科幻 悬疑 冒险'], ['https://movie.douban.com/subject/3011091/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p524964039.jpg', '忠犬八公的故事', "\xa0\xa0Hachi: A Dog's Tale", '9.4', '1097505', '永', '导演: 莱塞·霍尔斯道姆 Lasse Hallström\xa0\xa0\xa0主演: 理查·基尔 Richard Ger... 2009\xa0 \xa0美国 英国\xa0 \xa0剧情'], ['https://movie.douban.com/subject/1292001/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2574551676.jpg', '海上钢琴师', "\xa0\xa0La leggenda del pianista sull'oceano", '9.3', '1309525', '每', '导演: 朱塞佩·托纳多雷 Giuseppe Tornatore\xa0\xa0\xa0主演: 蒂姆·罗斯 Tim Roth ... 1998\xa0 \xa0意大利\xa0 \xa0剧情 音乐'], ['https://movie.douban.com/subject/1889243/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2614988097.jpg', '星际穿越', '\xa0\xa0Interstellar', '9.3', '1279562', '爱', '导演: 克里斯托弗·诺兰 Christopher Nolan\xa0\xa0\xa0主演: 马修·麦康纳 Matthew Mc... 2014\xa0 \xa0美国 英国 加拿大 冰岛\xa0 \xa0剧情 科幻 冒险'], ['https://movie.douban.com/subject/1292064/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p479682972.jpg', '楚门的世界', '\xa0\xa0The Truman Show', '9.3', '1192939', '如', '导演: 彼得·威尔 Peter Weir\xa0\xa0\xa0主演: 金·凯瑞 Jim Carrey 劳拉·琳妮 Lau... 1998\xa0 \xa0美国\xa0 \xa0剧情 科幻'], ['https://movie.douban.com/subject/3793023/', 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p579729551.jpg', '三傻大闹宝莱坞', '\xa0\xa03 Idiots', '9.2', '1463139', '英', '导演: 拉库马·希拉尼 Rajkumar Hirani\xa0\xa0\xa0主演: 阿米尔·汗 Aamir Khan 卡... 2009\xa0 \xa0印度\xa0 \xa0剧情 喜剧 爱情 歌舞'], ['https://movie.douban.com/subject/2131459/', 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p1461851991.jpg', '机器人总动员', '\xa0\xa0WALL·E', '9.3', '1032310', '小', '导演: 安德鲁·斯坦顿 Andrew Stanton\xa0\xa0\xa0主演: 本·贝尔特 Ben Burtt 艾丽... 2008\xa0 \xa0美国\xa0 \xa0科幻 动画 冒险'], ['https://movie.douban.com/subject/1291549/', 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p1910824951.jpg', '放牛班的春天', '\xa0\xa0Les choristes', '9.3', '1016057', '天', '导演: 克里斯托夫·巴拉蒂 Christophe Barratier\xa0\xa0\xa0主演: 热拉尔·朱尼奥 Gé... 2004\xa0 \xa0法国 瑞士 德国\xa0 \xa0剧情 音乐'], ['https://movie.douban.com/subject/1292213/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2455050536.jpg', '大话西游之大圣娶亲', '\xa0\xa0西遊記大結局之仙履奇緣', '9.2', '1169772', '一', '导演: 刘镇伟 Jeffrey Lau\xa0\xa0\xa0主演: 周星驰 Stephen Chow 吴孟达 Man Tat Ng... 1995\xa0 \xa0中国香港 中国大陆\xa0 \xa0喜剧 爱情 奇幻 古装'], ['https://movie.douban.com/subject/5912992/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p1363250216.jpg', '熔炉', '\xa0\xa0도가니', '9.3', '716680', '我', '导演: 黄东赫 Dong-hyuk Hwang\xa0\xa0\xa0主演: 孔侑 Yoo Gong 郑有美 Yu-mi Jung ... 2011\xa0 \xa0韩国\xa0 \xa0剧情'], ['https://movie.douban.com/subject/25662329/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2614500649.jpg', '疯狂动物城', '\xa0\xa0Zootopia', '9.2', '1408702', '迪', '导演: 拜伦·霍华德 Byron Howard 瑞奇·摩尔 Rich Moore\xa0\xa0\xa0主演: 金妮弗·... 2016\xa0 \xa0美国\xa0 \xa0喜剧 动画 冒险'], ['https://movie.douban.com/subject/1307914/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2564556863.jpg', '无间道', '\xa0\xa0無間道', '9.2', '958739', '香', '导演: 刘伟强 麦兆辉\xa0\xa0\xa0主演: 刘德华 梁朝伟 黄秋生 2002\xa0 \xa0中国香港\xa0 \xa0剧情 犯罪 悬疑'], ['https://movie.douban.com/subject/1291841/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p616779645.jpg', '教父', '\xa0\xa0The Godfather', '9.3', '716669', '千', '导演: 弗朗西斯·福特·科波拉 Francis Ford Coppola\xa0\xa0\xa0主演: 马龙·白兰度 M... 1972\xa0 \xa0美国\xa0 \xa0剧情 犯罪'], ['https://movie.douban.com/subject/1291560/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2540924496.jpg', '龙猫', '\xa0\xa0となりのトトロ', '9.2', '978455', '人', '导演: 宫崎骏 Hayao Miyazaki\xa0\xa0\xa0主演: 日高法子 Noriko Hidaka 坂本千夏 Ch... 1988\xa0 \xa0日本\xa0 \xa0动画 奇幻 冒险'], ['https://movie.douban.com/subject/1849031/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2614359276.jpg', '当幸福来敲门', '\xa0\xa0The Pursuit of Happyness', '9.1', '1178432', '平', '导演: 加布里尔·穆奇诺 Gabriele Muccino\xa0\xa0\xa0主演: 威尔·史密斯 Will Smith ... 2006\xa0 \xa0美国\xa0 \xa0剧情 传记 家庭'], ['https://movie.douban.com/subject/3319755/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p501177648.jpg', '怦然心动', '\xa0\xa0Flipped', '9.1', '1374010', '真', '导演: 罗伯·莱纳 Rob Reiner\xa0\xa0\xa0主演: 玛德琳·卡罗尔 Madeline Carroll 卡... 2010\xa0 \xa0美国\xa0 \xa0剧情 喜剧 爱情'], ['https://movie.douban.com/subject/6786002/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p1454261925.jpg', '触不可及', '\xa0\xa0Intouchables', '9.2', '763127', '满', '导演: 奥利维·那卡什 Olivier Nakache 艾力克·托兰达 Eric Toledano\xa0\xa0\xa0主... 2011\xa0 \xa0法国\xa0 \xa0剧情 喜剧']]